前往“校招VIP”小程序,访问更方便
ES的入门到精通系列
 csdn
10月20日
csdn
10月20日
转载声明:文章来源https://blog.csdn.net/fuwp18875261348/article/details/83757275
ES的安装与使用说明
ES服务只依赖于JDK,推荐使用JDK1.7+。
① 下载ES安装包
官方下载地址:https://www.elastic.co/downloads/elasticsearch
ES 5.2.2版本为例,下载对应的ZIP文件
② 运行ES
bin/elasticsearch.bat
③ 验证
访问:http://localhost:9200/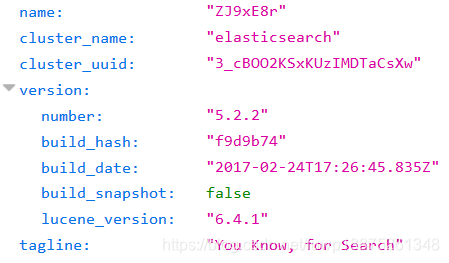
看到上图信息,恭喜你,你的ES集群已经启动并且正常运行.
注意:ES默认占用内存为2G,如果想修改其值,在conf/jvm.options文件中这里我们测试就用200m就够用了,如果启动报错或者运行不了,就是ES的设置错误
辅助管理工具Kibana5
① Kibana5.2.2下载地址:https://www.elastic.co/downloads/kibana
② 解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
③ 启动Kibana5 : bin\kibana.bat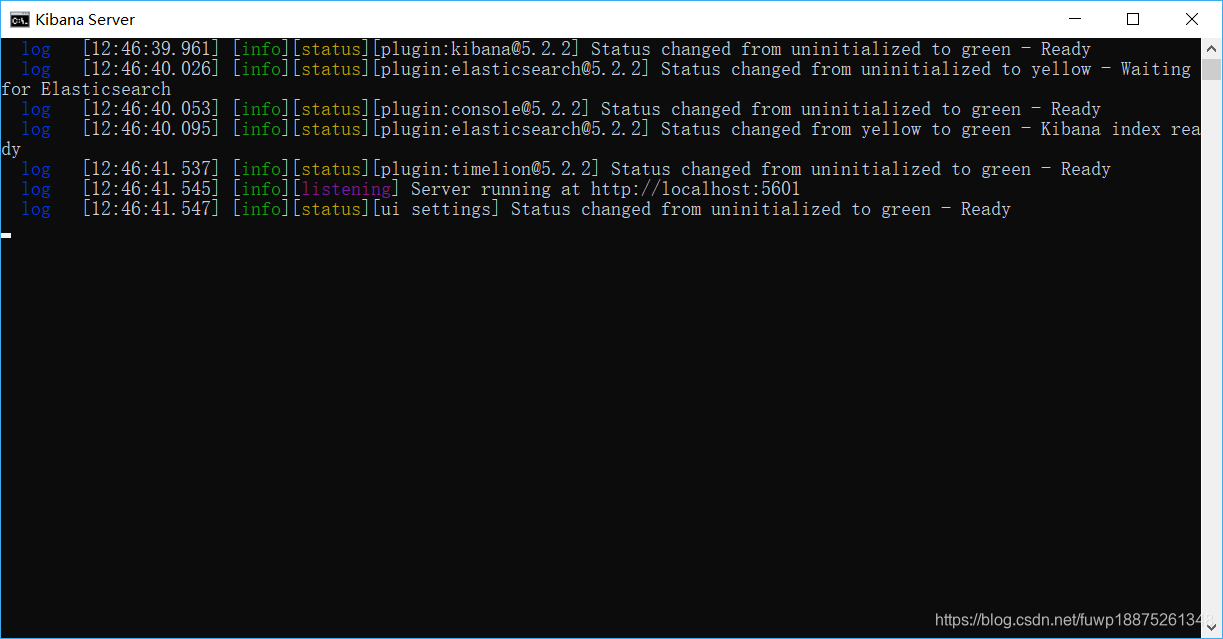
当从green变成Ready的时候,就说明Kibana就启动成功了
注意:必须联网才能正常启动,否则将启动失败
④ 默认访问地址:http://localhost:5601
ES数据管理:
ES文档的增删改查:
创建索引文档:
PUT {index}/{type}/{id}
{
"field": "value",
...
}ES响应内容:
{
"_index": "{index}",
"_type": "{type}",
"_id":{id},
"_version": 1, //文档版本号,每一次新增都会自增
"created": true //是否新增
}删:
DELETE {index}/{type}/{id}查:
获取指定ID的文档
GET {index}/{type}/{id}查询所有的文档
GET _search修改:
局部更新
POST {index}/{type}/{id}/_update
{
“doc” : {
"field": "value",
...
}
}批量操作:
Bulk请求体格式:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n每行必须以 “\n” 符号结尾,包括最后一行。
create当文档不存在时创建之。
index创建新文档或替换已有文档。
update局部更新文档。
delete删除一个文档。例如:
POST _bulk
{ "delete": { "_index": "itsource", "_type": "employee", "_id": "123" }}
{ "create": { "_index": "itsource", "_type": "blog", "_id": "123" }}
{ "title": "我发布的博客" }
{ "index": { "_index": "itsource", "_type": "blog" }}
{ "title": "我的第二博客" }注意:delete后不需要请求体,最后一行要有回车
分页查询:
例如:
GET _search?size=5&from=5size : 每页条数,默认 10
from : 跳过开始的结果数,默认 0
DSL查询与过滤:
过滤:
2.0以上的用法
{
"query": {
"bool": {
"must": [
{"match": {"description": "search" }}
],
"filter": {
"term": {"tags": "lucene"}
}
}
}
}DSL查询:
使用DSL查询,必须要传递query参数给ES。
GET itsource/employee/_search
{
"query": {
"match": {"sex":"女"}
},
"from": 20,
"size": 10,
" _source": ["fullName", "age", "email"],
"sort": [{"join_date": "desc"},{"age": "asc"}]
}上面的DSL查询语句代表:查询公司员工性别为女的员工,并按照加入时间降序、年龄升序排列,最终返回第21条至30条数据(只返回名字、年龄和email字段)
使用DSL查询与过滤的语法:
① 全匹配(match_all)
普通搜索(匹配所有文档):
{
"query" : {
"match_all" : {}
}
}如果需要使用过滤条件:
{
"query" : {
"bool" : {
"must" : [{
"match_all":{}
}],
"filter":{....}
}
}
}② 标准查询(match和multi_match)
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用match查询一个全文本字段,它会在真正查询之前用分析器先分析查询字符:
{
"query": {
"match": {
"fullName": "Steven King"
}
}
}上面的搜索会对Steven King分词,并找到包含Steven或King的文档,然后给出排序分值。
如果用 match 下指定了一个确切值,在遇到数字,日期,布尔值或者 not_analyzed的字符串时,它将为你搜索你给定的值,如:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}multi_match 查询允许你做 match查询的基础上同时搜索多个字段:
{
"query":{
"multi_match": {
"query": "Steven King",
"fields": [ "fullName", "title" ]
}
}
}上面的搜索同时在fullName和title字段中匹配。
提示:match一般只用于全文字段的匹配与查询,一般不用于过滤。
③单词搜索与过滤(Term和Terms)
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"tags": "elasticsearch"
}
}
}
}
}Terms搜索与过滤
{
"query": {
"terms": {
"tags": ["jvm", "hadoop", "lucene"],
"minimum_match": 2
}
}
}minimum_match:至少匹配个数,默认为1
④ 组合条件搜索与过滤(Bool)
组合搜索bool可以组合多个查询条件为一个查询对象,查询条件包括must、should和must_not。
例如:查询爱好有美女,同时也有喜欢游戏或运动,且出生于1990-06-30及之后的人。
{
"query": {
"bool": {
"must": [{"term": {"hobby": "美女"}}],
"should": [{"term": {"hobby": "游戏"}},
{"term": {"hobby": "运动"}}
],
"must_not": [
{"range" :{"birth_date":{"lt": "1990-06-30"}}}
],
"filter": [...],
"minimum_should_match": 1
}
}
}提示: 如果 bool 查询下没有must子句,那至少应该有一个should子句。但是 如果有 must子句,那么没有 should子句也可以进行查询。
⑤ 范围查询与过滤(range)
range过滤允许我们按照指定范围查找一批数据:
{
"query":{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
}上例中查询年龄大于等于20并且小于30。
gt:> gte:>= lt:< lte:<=
⑥ 存在和缺失过滤器(exists和missing)
{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"filter": {
"exists": { "field": "gps" }}
}
}
}
}提示:exists和missing只能用于过滤结果。
⑦ 前匹配搜索与过滤(prefix)
和term查询相似,前匹配搜索不是精确匹配,而是类似于SQL中的like ‘key%’
{
"query": {
"prefix": {
"fullName": "倪"
}
}
}上例即查询姓倪的所有人。
⑧ 通配符搜索(wildcard)
使用*代表0~N个,使用?代表1个。
{
"query": {
"wildcard": {
"fullName": "倪*华"
}
}
}文档映射Mapper:
默认映射:
查看索引类型的映射配置:
GET {indexName}/{typeName}/_mapping简单类型映射
针对单个类型的映射配置方式
POST {indexName}/{typeName}/_mapping
{
"{typeName}": {
"properties": {
"id": {
"type": "long"
},
"content": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}② 同时对多个类型的映射配置方式(推荐)
PUT {indexName}
{
"mappings": {
"user": {
"properties": {
"id": {
"type": "integer"
},
"info": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer"
}
}
},
"dept": {
"properties": {
"id": {
"type": "integer"
},
....更多字段映射配置
}
}
}
}对象及数组映射
① 对象的映射与索引
{
“id” : 1,
“girl” : {
“name” : “王小花”,
“age” : 22
}
}
对应的mapping配置:
{
"properties": {
"id": {"type": "long"},
"girl": {
"properties":{
"name": {"type": "keyword"},
"age": {"type": "long"}
}
}
}
}
注意:Lucene不理解内置对象,一个lucene文档包含键值对的一个扁平化列表,以便于ES索引内置对象,它把文档转换为类似这样:
{
"id": 1,
"girl.name":"王小花",
"girl.age":26
}
内置字段与名字相关,区分两个字段中相同的名字,可以使用全路径,例如user.girl.name②对象数组的映射
{
"id" : 1,
"girl":[{"name":"林志玲","age":32},{"name":"赵丽颖","age":22}]
}
对应的映射配置为:
"properties": {
"id": {
"type": "long"
},
"girl": {
"properties": {
"age": { "type": "long" },
"name": { "type": "text" }
}
}
}
注意:同内联对象一样,对象数组也会被扁平化索引
{
"user.girl.age": [32, 22],
"user.girl.name": ["林志玲", "赵丽颖"]
}全局映射全局映射
全局映射可以通过动态模板和默认设置两种方式实现。
默认方式:_default_动态模板:dynamic_templates
动态模板:dynamic_templates
如:
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
注意:ES会默认把string类型的字段映射为text类型(默认使用标准分词器)和对应的keyword类型Java API
ES的Maven引入
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>/**
* 获取客户端
* @return
* @throws Exception
*/
public TransportClient getClient() throws Exception {
// on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300));
return client;
}
/**
* 获取索引数据
* @throws Exception
*/
@Test
public void testIndex() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
// get 获取索引库的数据 id
GetResponse getResponse = client.prepareGet("crm", "user", "2").get();
// 响应的对象
System.out.println(getResponse.getSource());
// 关闭资源
client.close();
}
//添加
@Test
public void getCreate() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
IndexRequestBuilder prepareIndex = client.prepareIndex("crm", "user", "2");
//准备数据
Map<String,Object> map = new HashMap<String,Object>();
map.put("id",1);
map.put("name","haha");
map.put("age",18);
// 添加并发送给es
IndexResponse indexResponse = prepareIndex.setSource(map).get();
System.out.println(indexResponse);
// 关闭资源
client.close();
}
//删除
@Test
public void getDelete() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
//删除
DeleteResponse deleteResponse = client.prepareDelete("crm", "user", "2").get();
System.out.println(deleteResponse);
// 关闭资源
client.close();
}
//修改(原理:先删除以前的数据,再添加新的数据)
@Test
public void getUpdate() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
//准备数据
Map<String,Object> map = new HashMap<String,Object>();
map.put("id",4);
map.put("name","hehe");
map.put("age",21);
// 发送给es
UpdateResponse updateResponse = client.prepareUpdate("crm", "user", "2").setDoc(map).get();
System.out.println(updateResponse);
// 关闭资源
client.close();
}
/**
* 高级查询:
*/
//1 批量新添海量数据做测试
@Test
public void getBulk() throws Exception {
//获取客户端
TransportClient client = getClient();
//批量请求对象
BulkRequestBuilder bulk = client.prepareBulk();
//准备数据
for(int i =0;i<20;i++){
Map<String,Object> map = new HashMap<String,Object>();
map.put("id",i);
map.put("name","hehe");
map.put("age",i+2);
//添加数据
bulk.add(client.prepareIndex("crm","user",i+"").setSource(map));
}
//提交请求
BulkResponse bulkResponse = bulk.get();
if(bulkResponse.hasFailures()){
System.out.println("出错");
}
}
//高级查询条件:查询名字为hehe 年龄[5,8] 每页显示2条数据 按照年龄降序排序
@Test
public void query() throws Exception {
//构建排序对象
SortBuilder sort = new FieldSortBuilder("age");
sort.order(SortOrder.DESC);
//构建查询对象
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(new MatchQueryBuilder("name", "hehe"));
//构建filter过滤条件
List<QueryBuilder> filter = boolQueryBuilder.filter();
filter.add(new RangeQueryBuilder("age").gte(5).lte(8));
//构建搜索对象
SearchResponse searchResponse = getClient().prepareSearch("crm").setTypes("user").setFrom(0).setSize(2).addSort(sort).setQuery(boolQueryBuilder).get();
//返回结果
SearchHits hits = searchResponse.getHits();
System.out.println("总条数:"+hits.totalHits());
for (SearchHit searchHit : hits.getHits()) {
System.out.println(searchHit.getSource());
}
}回复

地瓜土到掉渣
05月24日
双非一本,荒废了三年,目前在准备考研冲211,但是现在计算机考研太难了,要是没考上的话估计也是找不到工作了,什么语言都学过一点,但是没有项目经历,只做过学校的一些小任务。我现在好焦虑,是努力考研还是从现在开始为找工作做准备,暑假开始还能在秋招中拿offer吗?
0
0
地瓜土到掉渣
04月08日
太强了,学完框架再回来看
0
0